Era da un po' che volevo scrivere sull'argomento e la preparazione della sessione che presenterò a TechDays/WPC tra un mese è stato il trigger di questo post.
Più di due anni fa ho iniziato a sviluppare delle librerie (oggi felicemente in funzione) per creare file conformi allo standard ECMA-376 che, in quanto membro della commissione ISO JTC1/SC34, spero di upgradare presto alla versione ISO DIS29500 recentemente approvata (ma ancora non utilizzata da alcuna applicazione sul mercato).
La beta della versione 2.0 dell'SDK fa un passo significativo in avanti rispetto alla 1.0. Mentre la 1.0 semplificava di fatto la gestione del package OPC dentro cui sono custoditi i file XML che descrivono i dati, la 2.0 aggiunge un aiuto stra-prezioso nella creazione dei dati stessi:
- un elaborato object model per generare il contenuto (non è quindi necessario scrivere XML)
- la validazione degli schemi
- il tool DocumentReflector che esegue legge un documento esistente e genera al volo il codice C# che produce quel documento. 10 e lode a chi ha creato questo tool.
- un tool di comparazione di due documenti ooxml
Il tool DocumentReflector è risolutivo nella gran parte di piccole applicazioni, soprattutto per la generazione di documenti destinati a Word. Si crea un documento con Word con formattazione, immagini e quant'altro, si carica il documento con questo tool, copia incolla del codice C# in un progetto, si inseriscono le variabili per personalizzare il documento e il gioco è fatto. A questo punto facendo un loop su una anagrafica si creano tutti i docx personalizzati.
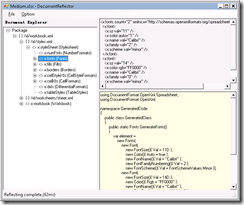
Ovviamente non è adatto a tutti gli scenari e infatti di questo parlerò nella mia sessione.
Ben diverso è uno spreadsheet che ha molta più variabilità e qui si toccano di più gli aspetti negativi dell'SDK.
Per esempio nei file XML è necessario sia presente l'attributo Count pari al numero di elementi child:
1: <x:fonts count="2" xmlns:x="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
2: <x:font>
3: <x:sz val="11" />
4: <x:color auto="1" />
5: <x:name val="Calibri" />
6: <x:family val="2" />
7: <x:scheme val="minor" />
8: </x:font>
9: <x:font>
10: <x:sz val="14" />
11: <x:color rgb="FF0000" />
12: <x:name val="Calibri" />
13: <x:family val="0" />
14: <x:scheme val="minor" />
15: </x:font>
16: </x:fonts>
Grazie a C# 3.0 e all'sdk, è possibile creare l'equivalente di quell'XML in questo modo:
1: new Fonts(
2: new Font(
3: new FontSize(){ Val = 11D },
4: new Color(){ Auto = true },
5: new FontName(){ Val = "Calibri" },
6: new FontFamilyNumbering(){ Val = 2 },
7: new FontScheme(){ Val = FontSchemeValues.Minor }),
8: new Font(
9: new FontSize(){ Val = 14D },
10: new Color(){ Rgb = "FF0000" },
11: new FontName(){ Val = "Calibri" },
12: new FontFamilyNumbering(){ Val = 0 },
13: new FontScheme(){ Val = FontSchemeValues.Minor })
14: ){ Count = (UInt32Value)2U },
Da notare la proprietà Count e l'attributo count nei due riquadri sopra.
La classe Fonts si comporta come una collection ma:
- la sua proprietà Count è finta, cioè deve essere valorizzata altrimenti vale null (non zero ma proprio null perché è una classe di OOXML SDK).
- l'omissione di qualsiasi dato mandatario comporta la creazione di un documento non valido (fortunatamente ci vengono in aiuto le classi di validazione)
Il vero difetto è che la libreria è data-oriented, cioè nata per specchiare i dati e quindi l'object model è poco potente e prono all'errore.
Nella mia libreria sono partito dal punto di vista opposto, cioè l'usabilità per lo sviluppatore e l'estremo strong-typing in modo da evitare "by design" errori che possano invalidare il file xml.
La creazione di uno di quegli elementi font nella mia libreria si scrive così:
1: XlsFontBase f = new XlsFont("Courier New", 12,
2: XlsFontFamilyType.NotApplicable, true, true,
3: false, XlsFontSchemeType.minor);
Inoltre non devo creare esplicitamente la sezione stili ma questa viene calcolata automaticamente dopo aver formattato lo spreadsheet. Perciò io mi limito a formattare le celle, poi la libreria estrapola il numero minimo di formattazioni necessarie, e quindi scrive lo stile di conseguenza.
Se ancora servisse, questo testimonia ancora una volta che sviluppare a partire dai dati può portare ad una complessità con cui bisogna fare i conti. Gli object model pensati fin dall'inizio secondo i paradigmi oop portano ad una semplificazione di tutta la logica e ad una maggiore usabilità (quindi meno bug!).
L'ultima considerazione sull'SDK 2.0 è che al momento non è chiaro come entrerà in gioco il neonato standard ISO e come verrà supportata la transizione tra i due standard. Tutto questo considerato che, dal punto di vista dello sviluppatore, lo standar de-facto è quello che conta, perciò dovremo vedere come avverrà la transizione ECMA -> ISO in Office 2010.
Per chi non conoscesse i dettagli, le differenze tra i due standard ci sono per motivi ovvi. ECMA ha presentato ad ISO il proprio standard e ISO ha chiesto delle (giuste e motivate) modifiche. Le differenze non sono qualitativamente rivoluzionarie ma sono pur sempre delle differenze che implicano un cambio di formato.