Questo post è basato su un problema reale che ho dovuto affrontare, l'obbiettivo era implementare una soluzione scalabile per un processo di elaborazione (back-end) di un software gestionale. La soluzione è stata costruita evolvendo l'esperienza pregressa sullo specifico requisito insieme a quella relativa a soluzioni multi-thread applicate a questo tipo di processi. Visto che l'architettura progettata e realizzata si è rivelata efficace voglio condividere aspetti specifici della soluzione.
Doverosa premessa
Chi ha esperienza nello scrivere soluzioni multi-thread sa bene che queste ultime non sono un vaso di pandora, per cui se io decido di usare i thread allora la mia applicazione è più veloce e scalabile. Ogni problema va attentamente studiato perchè può capitare che la strada del multi-thread, oppure la modalità con cui viene applicata, non sia la soluzione migliore ma anzi si riveli sbagliata. Questa premessa è doverosa perchè la soluzione proposta sia vista nella giusta ottica, cioè calata nel problema specifico (o nelle classe dei problemi) per cui è stata pensata e realizzata.
Contorni del problema
In sintesi il quesito era questo: Abbiamo a disposizione un servizio esterno costruito su filosofia SOA (Service Oriented Architecture) ed implementato attraverso l'esposizione di un servizio WEB basato su protocollo SOAP. Il servizio serve per l'archiviazione sostitutiva di documenti digitali. Ogni documento da archiviare richiede la chiamata di un metodo sul servizio esterno e corrisponde ad una transazione. La singola attività del processo è di fatto distribuita e possiamo scomporla come composta da tre fasi distinte:
- Preparazione del documento (sistema locale)
- Archiviazione sostitutiva (servizio remoto)
- Registrazione esito (sistema locale)
Il servizio esterno consuma la singola richiesta in un tempo relativamente basso ma significativo (mediamente un secondo). Per via delle specifiche caratteristiche dell'architettura tecnologica, il servizio è in grado di processare più richieste contemporaneamente senza riduzione delle prestazioni ma entro un livello massimo di richieste parallele, oltre il quale le prestazioni calano significativamente. La preparazione del documento ha un costo significativo in termini di elaborazione del sistema locale se rapportato alla registrazione dell'esito che è semplicimente il salvataggio di una ricevuta, ma comunque di un ordine di grandezza inferiore rispetto al tempo richiesto per la chiamata del servizio esterno.
Tenendo conto di questi presupposti il requisito era di riscrivere la procedura ottimizzandone le prestazioni. Questo richiedeva di realizzare una soluzione che garantisse maggiore scalabilità del processo, supportando l'elaborazione parallela di più documenti per la conservazione sostitutiva.
Architettura della soluzione
Prima di pensare a qualunque soluzione, un aspetto molto importante su cui è stato necessario prestare attenzione sono le caratteristiche della singola attività da processare. In particolare il tipo di task descritto si può scomporre nelle seguenti macro-fasi:
- Accesso in lettura all'archivio
- Preparazione del dato per il trasferimento
- Chiamata del servizio esterno
- Registrazione sull'archivio dell'esito
Di queste fasi l'unica veramente significativa in termini di carico CPU è la seconda la quale prevede una serie di operazioni CPU intensive per la preparazione del dato, le restanti hanno un rapporto bilanciato e dipendono soprattutto dalle prestazioni del file system e/o database e/o della rete locale, nella chiamata del servizio esterno, invece, è significativo il tempo di attesa sincrono, in cui il thread di esecuzione del metodo non fa niente, aspettando la risposta del sistema remoto. Di seguito riporto uno schizzo dell'andamento temporale della singola attività con evidenziate le fasi di carico significativo di CPU.
Diagramma esemplificativo carico attività

Le peculiari caratteristiche dell'attività mi hanno portato a scegliere un architettura basata su thread pool, dato che i task si prestano bene ad essere parallelizzati con un fattore dipendente dai limiti della piattaforma locale e del servizio esterno. Dopo attente valutazioni e confronti con i miei colleghi sono arrivato a formulare un architettura a tre livelli, il thread principale dell'applicazione (1), un worker thread, che si occupa delle fasi di inizializzazione, avvio, controllo del processo e generarezione dei task (2), i quali vengono eseguiti nel thread pool (3).
Diagramma esemplificativo architettura
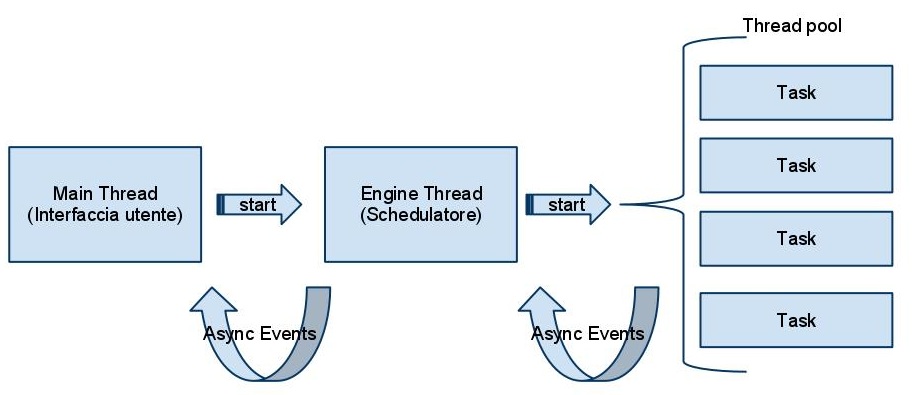
Il primo vantaggio di questa soluzione, nel caso il processo sia scomponibile in task indipendenti, è il basso livello di sincronizzazione richiesto, in pratica l'engine principale, che ho chiamato per convenzione Schedulatore, invia eventi asincroni all'interfaccia grafica per notificare segnalazioni, statistiche e termine del processo. Nel caso dei task l'uso degli eventi non è obbligatorio a meno che il processo sia composto da più tipologie di task per oggetto da elabarore o a fini di controllo o statistiche particolari, allora in questo caso può essere necessario generare ed intercettare eventi, tipicamente di termine del task. Quest'archiettura permette così di mantere basso il numero di lock. Un altro vantaggio importante è che è possibile e facile configurare e controllare il livello di parallelismo dei task all'interno del thread pool.
Aspetti tecnici della soluzione
Nei successivi post illustrerò alcuni passaggi principali della soluzione implementata su un prototipo che sto riscrevendo in VS 2010 con il .NET framework 4.0, la soluzione effettiva è stata implementata con il .NET framework 3.5 il quale pur avendo tutti gli strumenti per poter lavorare con il thread pool, non dispone di facilatori come la classe Task o le Parallel Extension. La mia idea è di illustrare le parti fondamentali della soluzione confrontando le alternative evolute perchè è probabile che, come nel mio caso non potete già utilizzare il .NET 4.0 per vincoli del vostro progetto ma vi farebbe piacere valutare in prospettiva le alternative tecniche offerte dal nuovo framework.